앞에서 살펴본 em과 rem은 주변 상황에 따라 그 크기를 달리할 수 있는 가변성을 지니고 있지만, 브라우저나 기기 화면에 크기에 따라 크기가 달라지는 단위는 아니다. 따라서 진정한 반응형 단위라고 할 수 는 없다.
반응하는 단위들
아래 몇 가지 단위들은 뷰포트 크기를 기반으로 값을 계산하여 크기를 결정하는 가변 단위이다.
font-size: 1vw; /* 뷰포트 너비의 100분의 1 */
font-size: 1vh; /* 뷰포트 높이의 100분의 1 */
/* 뷰포트 높이와 너비 중 작은 쪽의 100분의 1 */
font-size: 1vmin;
/* 뷰포트 높이와 너비 중 큰 쪽의 100분의 1 */
font-size: 1vmax;
사용해보자
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>다른 상대 단위들</title>
<style>
p{
margin: 0;
font-size: 50vw;
}
</style>
</head>
<body>
<p>왕왕</p>
</body>
</html>
위 소스를 확인해보면
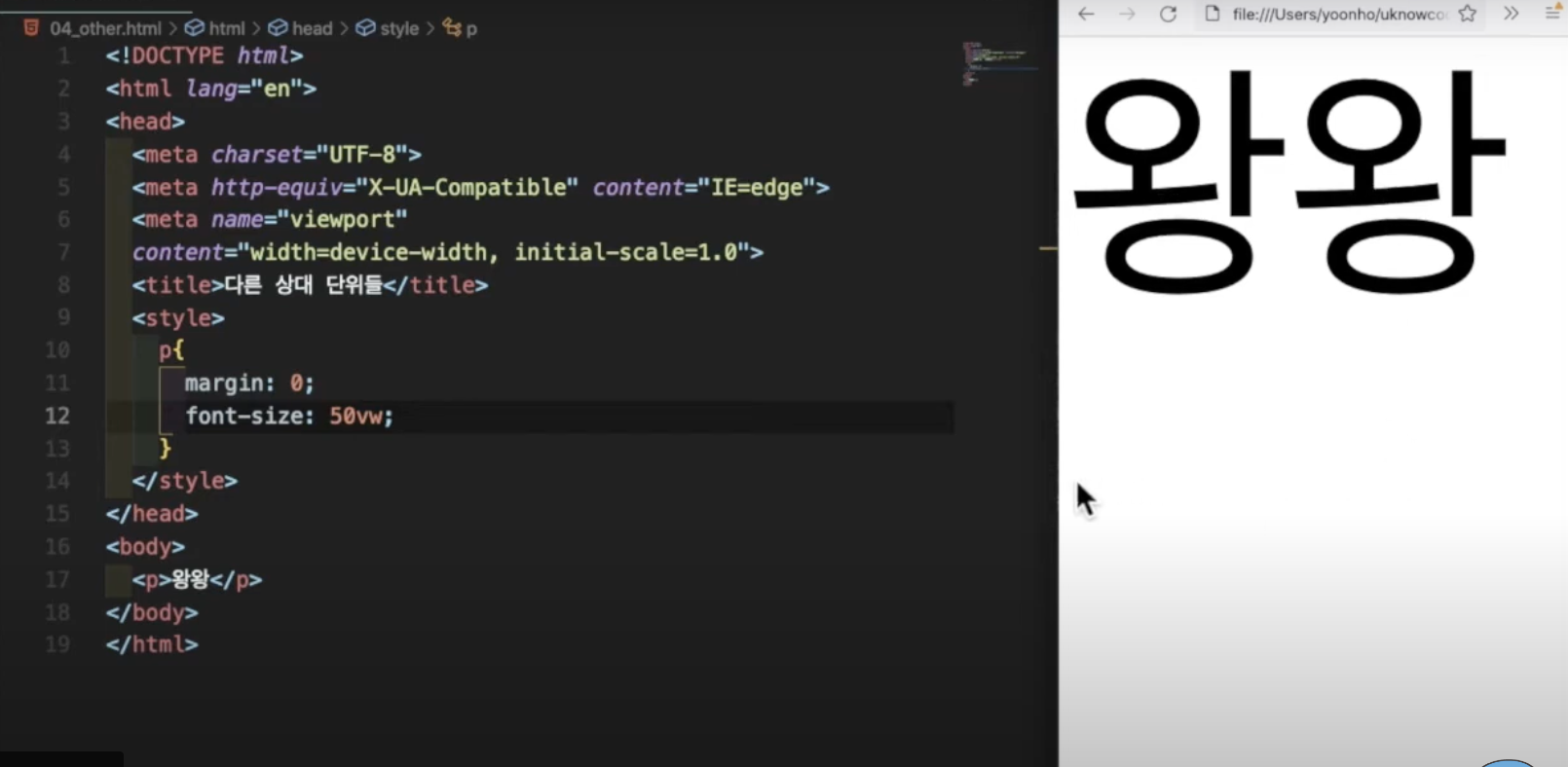
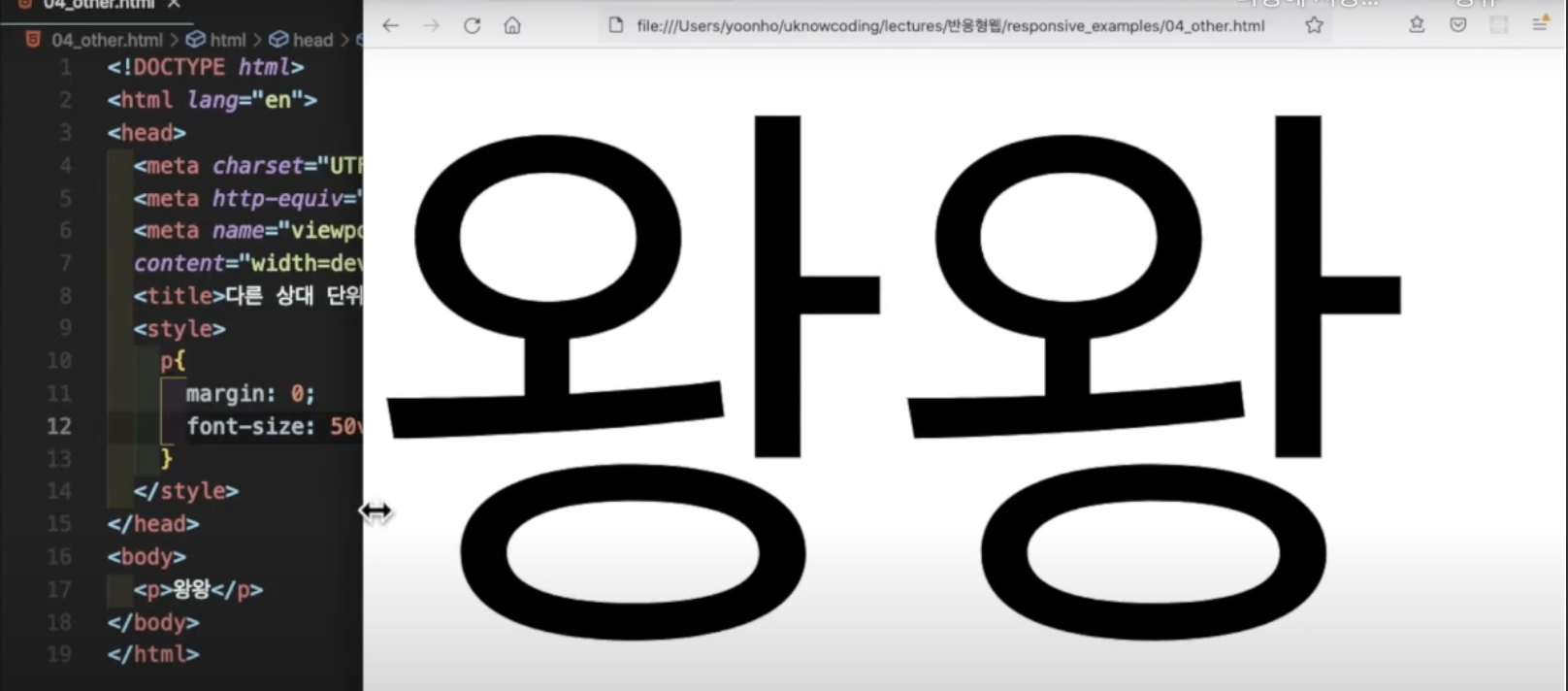
브라우저의 크기에 따라 글씨의 크기가 달라지는 것을 확인할 수 있다.
뷰포트 높이로 설정을 변경해보자
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>다른 상대 단위들</title>
<style>
p{
margin: 0;
font-size: 50vh;
}
</style>
</head>
<body>
<p>왕왕</p>
</body>
</html>

이제는 넓이에는 영향을 받지 않는다.

브라우저 창의 높이를 줄이면 글씨가 작아지게 된다.
정리

'Front-End > 반응형 웹' 카테고리의 다른 글
| 반응형 웹(6) - 미디어 쿼리 (0) | 2024.07.17 |
|---|---|
| 반응형 웹(5) - calc() (0) | 2024.07.15 |
| 반응형 웹(4) - 가변형 레이아웃 (2) | 2024.07.14 |
| 반응형 웹(2) em & rem (0) | 2024.07.09 |
| 반응형 웹(1) (0) | 2024.07.08 |