검색(Searching)은 배열이나 리스트 같은 데이터 집합에서 특정 값(또는 조건에 맞는 요소)을 찾아내는 과정이다.
예를 들어, 반에서 학생들 이름이 적힌 명단이 있을 때 "철수"라는 이름을 찾는 것과 비슷하다.
왜 검색이 필요할까?
데이터 찾기 : 많은 데이터 중에서 필요한 정보를 빠르게 찾기 위해 사용된다.
알고리즘 문제 : 코딩 테스트에서 특정 값을 찾는 문제가 출제된다.
효율성 : 올바른 검색 알고리즘을 사용하면 데이터의 양이 많더라도 빠른 시간 안에 원하는 값을 찾을 수 있다.
1. 선형 검색(Linear Search)
배열의 첫 번째 요소부터 순서대로 하나씩 검사하면서 찾고자 하는 값과 일치하는지 확인한다.
특징
간단하고 구현하기 쉽다
데이터가 정렬되어 있지 않아도 사용할 수 있다.
최악의 경우 모든 요소를 확인해야 하므로, 시간 복잡도는 O(n)이다.
// 선형 검색 함수: 배열에서 target 값을 찾으면 해당 인덱스를 반환하고, 없으면 null 반환
fun linearSearch(arr: Array<Int>, target: Int): Int? {
for (i in arr.indices) {
if (arr[i] == target) {
return i // 찾은 경우 해당 인덱스 반환
}
}
return null // 값이 없으면 null 반환
}
fun main() {
val numbers = arrayOf(5, 3, 8, 4, 2, 10)
val target = 4
val index = linearSearch(numbers, target)
if (index != null) {
println("선형 검색: $target 값은 인덱스 $index 에 있습니다.")
} else {
println("선형 검색: $target 값을 찾을 수 없습니다.")
}
}
// arr.indices 는 배열의 인덱스 범위를 반환한다.
// 각 요소를 순차적으로 검사하여, target 값과 일치하면 해당 인덱스를 반환한다.
2. 이진 검색(Binary Search)
정렬된 배열을 반으로 나누어 원하는 값이 어느 쪽에 있는지 판단하여 검색 범위를 좁혀가는 방식이다.
특징
배열이 정렬되어 있어야 사용할 수 있다.
매 반복마다 검색 범위가 절반으로 줄어들기 때문에, 시간 복잡도는 O(log n)으로 매우 효율적이다.
// 이진 검색 함수: 정렬된 배열에서 target 값을 찾으면 해당 인덱스를 반환, 없으면 null 반환
fun binarySearch(arr: Array<Int>, target: Int): Int? {
var low = 0
var high = arr.size - 1
while (low <= high) {
val mid = (low + high) / 2 // 중간 인덱스 계산
when {
arr[mid] == target -> return mid // 중간 값이 target이면 반환
arr[mid] < target -> low = mid + 1 // target이 더 크면 오른쪽 범위로 좁힘
else -> high = mid - 1 // target이 더 작으면 왼쪽 범위로 좁힘
}
}
return null // target 값을 찾지 못하면 null 반환
}
fun main() {
val sortedNumbers = arrayOf(2, 3, 4, 5, 8, 10) // 이진 검색을 위해 정렬된 배열 필요
val target = 5
val index = binarySearch(sortedNumbers, target)
if (index != null) {
println("이진 검색: $target 값은 인덱스 $index 에 있습니다.")
} else {
println("이진 검색: $target 값을 찾을 수 없습니다.")
}
}
// 배열이 정렬되어 있다는 전제하에, low와 high 인덱스를 사용해 중간 mid을 계산한다.
다른 사람이 테이블에 대해 SELECT나 UPDATE를 하고 있거나, 트랜잭션이 열려 있어서 락이 걸려 있는 상태이다. Oracle은 ALTER TABLE 같은 DDL 문장을 실행할 때 해당 테이블에 대해 exclusive lock을 걸려고 시도하는데, 이미 누군가 쓰고 있다면 그 락을 못 걸고 에러가 난다.
누군가 테이블을 사용하고 있군...
해결 방법
잠깜 기다렸다가 다시 시도 : 누군가 사용하고 있다는건 일시적인 현상이므로 가장 직관적인 해결 방법인것 같다.
락 걸린 세션 확인하기(DBA 권한 필요)
락 잡고 있는 세션 종료(주의! 꼭 필요한 경우에만 진행한다.)
* 락 걸린 세션 확인 쿼리
SELECT
l.session_id,
s.serial#,
s.username,
s.status,
o.object_name
FROM
v$locked_object l
JOIN dba_objects o ON l.object_id = o.object_id
JOIN v$session s ON l.session_id = s.sid
WHERE
o.object_name = 'A';
정렬(sorting)은 데이터 (예: 숫자, 문자열 등)를 일정한 순서대로 나열하는 과정이다. 예를 들어, 시험 점수가 섞여 있을 때 낮은 점수부터 높은 점수 순서대로 정렬하면, 누구의 점수가 가장 낮고 누구의 점수가 가장 높은지 쉽게 알 수 있다.
왜 정렬이 필요할까?
검색 : 정렬된 데이터를 빠르게 검색할 수 있다.
분석 : 데이터를 정리해서 보고서나 그래프로 만들 때, 정렬된 상태가 더 유용하다.
문제 해결 : 코딩 테스트나 알고리즘 문제에서 정렬은 자주 사용되는 기본 기술이다.
버블 정렬(Bubble Sort) 이해하기
버블 정렬의 원리
버블 정렬은 인접한 두 개의 원소를 비교하여 순서가 맞지 않으면 서로 교환한다.
한 번의 반복(패스)마다 가장 큰 값이 맨 뒤로 이동하게 된다.
이 과정을 전체 배열이 정리될 때까지 반복한다.
버블 정렬 알고리즘의 단계별 설명
배열의 첫 번째와 두 번째 요소를 비교한다. 만약 첫 번째가 두 번째보다 크다면 서로 교환한다.
두 번째와 세 번째 요소를 비교하고, 필요하면 교환한다.
배열 끝까지 이 과정을 반복하면, 한 번의 반복 후 가장 큰 값이 배열의 끝으로 이동한다.
배열의 크기만큼 (또는 더 적은 횟수로) 반복하여 전체 배열을 정렬한다.
버블 정렬의 단점
비교와 교환이 반복되기 때문에, 데이터가 많을 경우 시간이 많이 걸린다. 시간복잡도 O(n^2)
버블 정렬 예제 코드
// 버블 정렬 함수: 배열을 오름차순으로 정렬
fun bubbleSort(arr: Array<Int>): Array<Int> {
// 배열의 길이를 저장합니다.
val n = arr.size
// 전체 배열을 n-1번 반복합니다.
for (i in 0 until n - 1) {
// 각 반복마다 인접한 두 원소를 비교합니다.
for (j in 0 until n - i - 1) {
// 만약 현재 원소가 다음 원소보다 크다면, 두 원소의 위치를 교환합니다.
if (arr[j] > arr[j + 1]) {
// 교환 로직
val temp = arr[j]
arr[j] = arr[j + 1]
arr[j + 1] = temp
// 교환 후 로그 출력 (각 단계별 상태 확인)
println("교환 후 배열 상태: ${arr.joinToString(", ")}")
}
}
}
return arr
}
fun main() {
val numbers = arrayOf(64, 34, 25, 12, 22, 11, 90)
println("원래 배열: ${numbers.joinToString(", ")}")
val sortedNumbers = bubbleSort(numbers)
println("정렬된 배열: ${sortedNumbers.joinToString(", ")}")
}
실행 결과
원래 배열: 64, 34, 25, 12, 22, 11, 90
교환 후 배열 상태: 34, 64, 25, 12, 22, 11, 90
교환 후 배열 상태: 34, 25, 64, 12, 22, 11, 90
교환 후 배열 상태: 34, 25, 12, 64, 22, 11, 90
교환 후 배열 상태: 34, 25, 12, 22, 64, 11, 90
교환 후 배열 상태: 34, 25, 12, 22, 11, 64, 90
교환 후 배열 상태: 25, 34, 12, 22, 11, 64, 90
교환 후 배열 상태: 25, 12, 34, 22, 11, 64, 90
교환 후 배열 상태: 25, 12, 22, 34, 11, 64, 90
교환 후 배열 상태: 25, 12, 22, 11, 34, 64, 90
교환 후 배열 상태: 12, 25, 22, 11, 34, 64, 90
교환 후 배열 상태: 12, 22, 25, 11, 34, 64, 90
교환 후 배열 상태: 12, 22, 11, 25, 34, 64, 90
교환 후 배열 상태: 12, 11, 22, 25, 34, 64, 90
교환 후 배열 상태: 11, 12, 22, 25, 34, 64, 90
정렬된 배열: 11, 12, 22, 25, 34, 64, 90
재귀 함수란 자기 자신을 호출하는 함수이다. 즉, 문제를 해결하기 위해 동일한 문제의 더 작은 버전을 반복해서 호출하는 방식이다.
재귀 함수의 구성 요소
기본 조건(Base Case) : 재귀 호출을 멈추는 조건이다. 기본 조건이 없으면 함후가 무한히 자기 자신을 호출하게되는 무한루프에 빠지게 된다.
재귀 호출(Recursive Case) : 문제를 더 작은 문제로 나누어 자기 자신을 호출하는 부분이다.
재귀 함수 예제
1. 팩토리얼 계산(n!)
fun factorial(n: Int): Int {
// 기본 조건: n이 0이면 1 반환
if (n == 0) {
return 1
}
// 재귀 호출: n * (n-1)! 계산
return n * factorial(n - 1)
}
fun main() {
val number = 5
println("$number! = ${factorial(number)}") // 출력: 5! = 120
}
2. 피보나치 수열 계산
피보나치 수열은 앞의 두 수의 합으로 다음 수를 만드는 수열이다.
재귀적으로 f(n) = f(n-1) + f(n-2)로 정의되며, f(0)=0, f(1)=1 이다.
fun fibonacci(n: Int): Int {
// 기본 조건: n이 0 또는 1이면 n 반환
if (n == 0 || n == 1) {
return n
}
// 재귀 호출: 피보나치 수열의 합 계산
return fibonacci(n - 1) + fibonacci(n - 2)
}
fun main() {
val n = 10
println("Fibonacci($n) = ${fibonacci(n)}") // 예시 출력: Fibonacci(10) = 55
}
3. 문자열 재귀적으로 뒤집기
- 문제 설명 : 문자열을 재귀 함수를 사용하여 뒤집는 코드를 작성해보자
- 힌트 : 문자열의 첫 번째 문자와 나머지 부분을 분리하여, 나머지 부분을 재귀적으로 뒤집고 첫 번째 문자를 맨 뒤에 붙이는 방식으로 접근해보자
fun reverseRecursively(str: String): String {
// 기본 조건: 문자열이 비어있으면 그대로 반환
if (str.isEmpty()) {
return str
}
// 재귀 호출: 문자열의 첫 번째 문자를 마지막으로 보내고, 나머지 문자열을 뒤집음
return reverseRecursively(str.substring(1)) + str[0]
}
fun main() {
val text = "Hello"
println("원래 문자열: $text")
println("뒤집은 문자열: ${reverseRecursively(text)}")
// 출력: 뒤집은 문자열: olleH
}
fun countWords(sentence: String): Int {
// 공백을 기준으로 단어 분리 후, 분리된 리스트의 크기를 반환
val words = sentence.trim().split("\\s+".toRegex())
return words.size
}
fun main() {
val sentence = "Kotlin is fun and powerful"
println("단어 개수: ${countWords(sentence)}")
// 출력: 단어 개수: 5
}
// val words = sentence.trim().split("\\s+".toRegex()) 동작 순서
// 1. sentence.trim()
// 동작: 입력된 문자열 sentence의 앞뒤(시작과 끝)에 있는 불필요한 공백(스페이스, 탭 등)을 제거합니다.
// 예시: " Hello Kotlin! " → "Hello Kotlin!"
// 2. .split("\\s+".toRegex())
// 동작:
// trim()으로 정리된 문자열을 기준으로, 하나 이상의 공백 문자(정규표현식 \\s+)를 찾아서 해당 부분에서 문자열을 나눕니다.
// \\s+는 정규 표현식에서 "하나 이상의 공백 문자"를 의미합니다.
// .toRegex()는 문자열 "\\s+"를 정규식 객체로 변환해줍니다.
// 예시: "Hello Kotlin!" → ["Hello", "Kotlin!"]
fun multiply(a: Int, b: Int): Int {
return a * b
}
fun divide(a: Int, b: Int): Int {
if (b == 0) {
println("0으로 나눌 수 없습니다.")
return 0 // 또는 적절한 예외 처리를 할 수 있음
}
return a / b
}
fun main() {
println("곱셈 결과: ${multiply(10, 5)}") // 출력: 50
println("나눗셈 결과: ${divide(10, 2)}") // 출력: 5
println("나눗셈 결과: ${divide(10, 0)}") // 출력: 0과 "0으로 나눌 수 없습니다." 메시지
}
2. 학생 성적 평균 구하기
- 문제 설명 : 학생들의 성적이 저장된 리스트가 주어질 때, 모든 학생의 평균 성적을 계산하여 출력하는 코드를 작성해보자
- 힌트 : 가변 리스트 또는 불변 리스트를 사용하여 성적 데이터를 저장한다. 리스트의 모든 요소를 합산한 후, 리스트의 크기로 나눈다.
fun calculateAverage(scores: List<Int>): Double {
var sum = 0
for (score in scores) {
sum += score
}
return sum.toDouble() / scores.size
}
fun main() {
val scores = listOf(80, 90, 100, 70, 60)
println("평균 성적: ${calculateAverage(scores)}") // 출력: 평균 성적: 80.0
}
3. 짝수만 출력
- 문제 설명 : 정수 리스트가 주어졌을 때, 리스트에서 짝수인 숫자만 출력하는 코드를 작성해보자
fun findMax(arr: Array<Int>): Int {
var max = arr[0]
for (num in arr) {
if (num > max) {
max = num
}
}
return max
}
fun main() {
val numbers = arrayOf(10, 20, 30, 40, 50)
println("최대값: ${findMax(numbers)}")
}
* 관련해서 더 알아보아야 하는 것 : Docker를 이용해 여러 개의 Spring Boot 컨테이너를 실행하고, Kubernetes를 사용하여 Auto Scaling 기능을 적용하는 방법을 찾아보자.
3-2. 부하 분산(Load Balancing)
부하 분산은 사용자 요청을 여러 서버에 골고루 분산시켜 한 서버에 부담이 집중되지 않도록 하는 기술이다. 음식점에서 한 웨이터가 모든 손님을 상대하기 어려우니, 여러 웨이터가 각 테이블을 나누어 케어하는 것과 같다.
Spring Boot 애플리케이션은 외부 로드 밸런서(Nginx, HAProxy, AWS ELB 등)와 함께 사용하여 부하 분산을 쉽게 구현할 수 있다.
직접 로드 밸런싱 코드를 작성하는게 아니라 로드 밸런서 설정 파일을 통해 서버 간 트래픽 분산을 관리한다.
Nginx 설정 일부 예시 :
upstream spring_backend {
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://spring_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
3-3. 캐싱(Caching)
캐싱은 자주 사용되는 데이터를 미리 저장해 두어, 데이터베이스나 다른 서버에 매번 접근하지 않고 빠르게 응답하는 기술이다. 냉장고에 좋아하는 간식을 미리 저장해두면, 매번 마트에 가지 않고도 간식을 즐길 수 있는 걸 생각하면 비슷하다.
Spring Boot는 Redis와 같은 캐시 솔루션과 쉽게 통합할 수 있다.
Redis 캐시 설정 및 사용 예시 : 1. build.gradle.kts에 Redis 의존성 추가
dependencies {
implementation("org.springframework.boot:spring-boot-starter-data-redis")
// ... 기타 의존성
}
2. applicaiton.properties에 Redis 설정 추가
# Redis 서버 설정 (로컬에서 Redis가 실행 중임을 가정합니다)
spring.redis.host=localhost
spring.redis.port=6379
# 기본 서버 포트 (8080번 포트로 실행)
server.port=8080
3. Kotlin 코드 예제 - 캐시 서비스 구현
CacheService.kt
package com.example.demo.service
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.redis.core.RedisTemplate
import org.springframework.stereotype.Service
import java.util.concurrent.TimeUnit
/**
* CacheService 클래스는 Redis를 이용하여 캐시 기능을 제공하는 서비스이다.
* 이 클래스에서는 데이터를 캐시에 저장(setCache)하고, 조회(getCache)하는 기능을 구현한다.
*/
@Service
class CacheService(@Autowired val redisTemplate: RedisTemplate<String, String>) {
/**
* setCache 함수는 지정된 key와 value를 캐시에 저장합니다.
* timeout은 캐시에 데이터가 유지될 시간(초)입니다.
*/
fun setCache(key: String, value: String, timeout: Long = 60) {
// opsForValue()는 단순한 key-value 캐싱에 사용됩니다.
redisTemplate.opsForValue().set(key, value, timeout, TimeUnit.SECONDS)
}
/**
* getCache 함수는 지정된 key에 해당하는 캐시된 값을 반환합니다.
* 만약 캐시에 값이 없으면 null을 반환합니다.
*/
fun getCache(key: String): String? {
return redisTemplate.opsForValue().get(key)
}
}
AsyncService.kt
package com.example.demo.service
import org.springframework.scheduling.annotation.Async
import org.springframework.stereotype.Service
/**
* AsyncService 클래스는 비동기 작업을 처리하기 위한 서비스이다.
* @Async 어노테이션을 사용하여, 이 클래스의 메서드가 호출될 때 즉시 반환되고,
* 별도의 스레드에서 작업을 수행하게 된다.
*/
@Service
class AsyncService {
/**
* doAsyncWork 함수는 3초 동안 대기한 후 "비동기 작업 완료!" 메시지를 콘솔에 출력한다.
* 이 함수는 @Async 어노테이션 덕분에 호출 즉시 비동기적으로 실행된다.
*/
@Async
fun doAsyncWork() {
// 3초간 대기하여, 긴 작업을 비동기적으로 처리하는 예제를 시뮬레이션한다.
Thread.sleep(3000)
println("비동기 작업 완료!")
}
}
DemoController.kt
package com.example.demo.controller
import com.example.demo.service.AsyncService
import com.example.demo.service.CacheService
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RestController
/**
* DemoController는 REST API를 제공하는 컨트롤러이다.
* 이 컨트롤러는 캐시 기능과 비동기 작업 기능을 테스트하기 위한 API를 제공한다.
*/
@RestController
class DemoController(
val cacheService: CacheService, // CacheService를 주입받아 캐시 기능을 사용한다.
val asyncService: AsyncService // AsyncService를 주입받아 비동기 작업을 수행한다.
) {
/**
* /ping API는 캐시에서 "greeting" 키의 값을 조회하고,
* 값이 없다면 "pong"을 캐시에 저장한다.
* 동시에 비동기 작업을 실행하고, "pong"을 응답한다.
*/
@GetMapping("/ping")
fun ping(): String {
val key = "greeting"
// 캐시에서 key "greeting"의 값을 가져온다.
var value = cacheService.getCache(key)
// 만약 캐시에 값이 없으면,
if (value == null) {
value = "pong"
// 캐시에 60초 동안 "pong" 값을 저장한다.
cacheService.setCache(key, value, 60)
}
// 비동기 작업을 실행한다.
// 이 작업은 백그라운드에서 3초 후 완료된다.
asyncService.doAsyncWork()
// "pong"을 응답으로 반환한다.
return value
}
}
3-4. 비동기 처리와 큐
사용자의 요청을 즉시 처리하지 않고, 큐에 저장한 후 차례대로 처리하는 방식이다. (인터파크에서 앞에 몇명이 남았다고 알려주는게 큐를 사용해서 그런게 아닐까?) 놀이공원에서 사람들이 대기열에 서 있다가 순서대로 놀이기구를 타는 것처럼, 요청을들 순차적으로 처리한다.
@Async 어노테이션을 사용하면 쉽게 비동기 작업을 구현할 수 있다.
간단한 예제를 보면
// AsyncService.kt
package com.example.demo.service
import org.springframework.scheduling.annotation.Async
import org.springframework.stereotype.Service
/**
* AsyncService는 긴 작업을 비동기적으로 처리하는 서비스이다.
* @Async 어노테이션을 사용하여, 이 메서드가 호출되면 별도의 스레드에서 실행된다.
*/
@Service
class AsyncService {
/**
* doAsyncWork 함수는 3초간 대기 후 콘솔에 "비동기 작업 완료!" 메시지를 출력한다.
*/
@Async
fun doAsyncWork() {
// 3000 밀리초 (3초) 동안 대기한다.
Thread.sleep(3000)
println("비동기 작업 완료!")
}
}
비동기에 대해서 감이 안올수 있다. Controller에서 비동기를 호출 후 처리하는 간단한 예제를 살펴보자
// DemoController.kt
package com.example.demo.controller
import com.example.demo.service.AsyncService
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RestController
/**
* DemoController는 간단한 REST API를 제공하여, 비동기 작업을 테스트할 수 있게 한다.
*/
@RestController
class DemoController(val asyncService: AsyncService) {
/**
* /asyncTest 경로를 호출하면, 비동기 작업이 실행되고 즉시 응답을 반환
*/
@GetMapping("/asyncTest")
fun asyncTest(): String {
asyncService.doAsyncWork() // 비동기 작업 실행
return "비동기 작업이 시작되었습니다!"
}
}
위 코드가 어떻게 동작할까? 사용자가 /asyncTest API를 호출하면, 서버는 즉시 "비동기 작업이 시작되었습니다!" 라는 응답을 반환하고, 백그라운드에서 3초 후 "비동기 작업 완료!" 메세지를 콘솔에 출력한다. 순서대로 실행되는게 아니다.
Spring Boot와 Kotlin에서 간단한 메시지 큐를 구현해보자(RabbitMQ 사용)
1. build.gradle.kts에 의존성 추가
dependencies {
// RabbitMQ와 Spring Boot 연동을 위한 의존성
implementation("org.springframework.boot:spring-boot-starter-amqp")
// 기타 의존성...
}
2. application.properties에 RabbitMQ 설정
# RabbitMQ 서버 설정 (기본적으로 로컬에서 실행 중이라고 가정)
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
메세지 큐 서비스 구현
// MessageQueueService.kt
package com.example.demo.service
import org.springframework.amqp.rabbit.annotation.RabbitListener
import org.springframework.amqp.rabbit.core.RabbitTemplate
import org.springframework.stereotype.Service
/**
* MessageQueueService는 RabbitMQ를 사용하여 메시지 큐를 통한 비동기 처리를 구현한 서비스
*/
@Service
class MessageQueueService(val rabbitTemplate: RabbitTemplate) {
/**
* sendMessage 함수는 지정한 메시지를 "queue.tetris" 큐로 전송한다.
*/
fun sendMessage(message: String) {
rabbitTemplate.convertAndSend("queue.tetris", message)
}
/**
* receiveMessage 함수는 "queue.tetris" 큐를 구독하여 메시지를 수신한다.
* 메시지가 수신되면 콘솔에 출력하고, 필요한 추가 처리를 수행할 수 있다.
*/
@RabbitListener(queues = ["queue.tetris"])
fun receiveMessage(message: String) {
println("메시지 수신: $message")
// 메시지 처리 로직을 여기에 작성할 수 있다.
}
}
위에서 만든 메시지 큐를 활용하는 Controller 를 만들어보자.
// QueueController.kt
package com.example.demo.controller
import com.example.demo.service.MessageQueueService
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RestController
/**
* QueueController는 메시지 큐를 통해 작업을 비동기적으로 처리하는 API를 제공
*/
@RestController
class QueueController(val messageQueueService: MessageQueueService) {
/**
* /queueTest 경로를 호출하면, "테트리스 블럭 이동"과 같은 작업 메시지를 큐에 전송한다.
*/
@GetMapping("/queueTest")
fun queueTest(): String {
// 메시지 큐에 메시지를 전송한다.
messageQueueService.sendMessage("테트리스 블럭 이동")
return "메시지가 큐에 전송되었습니다!"
}
}
사용자가 /queueTest API를 호출하면 메시지 "테트리스 블록 이동"이 RabbitMQ 큐에 전송되고, 해당 큐를 구독 중인 receiveMessage 메서드가 메시지를 수신하여 처리한다.
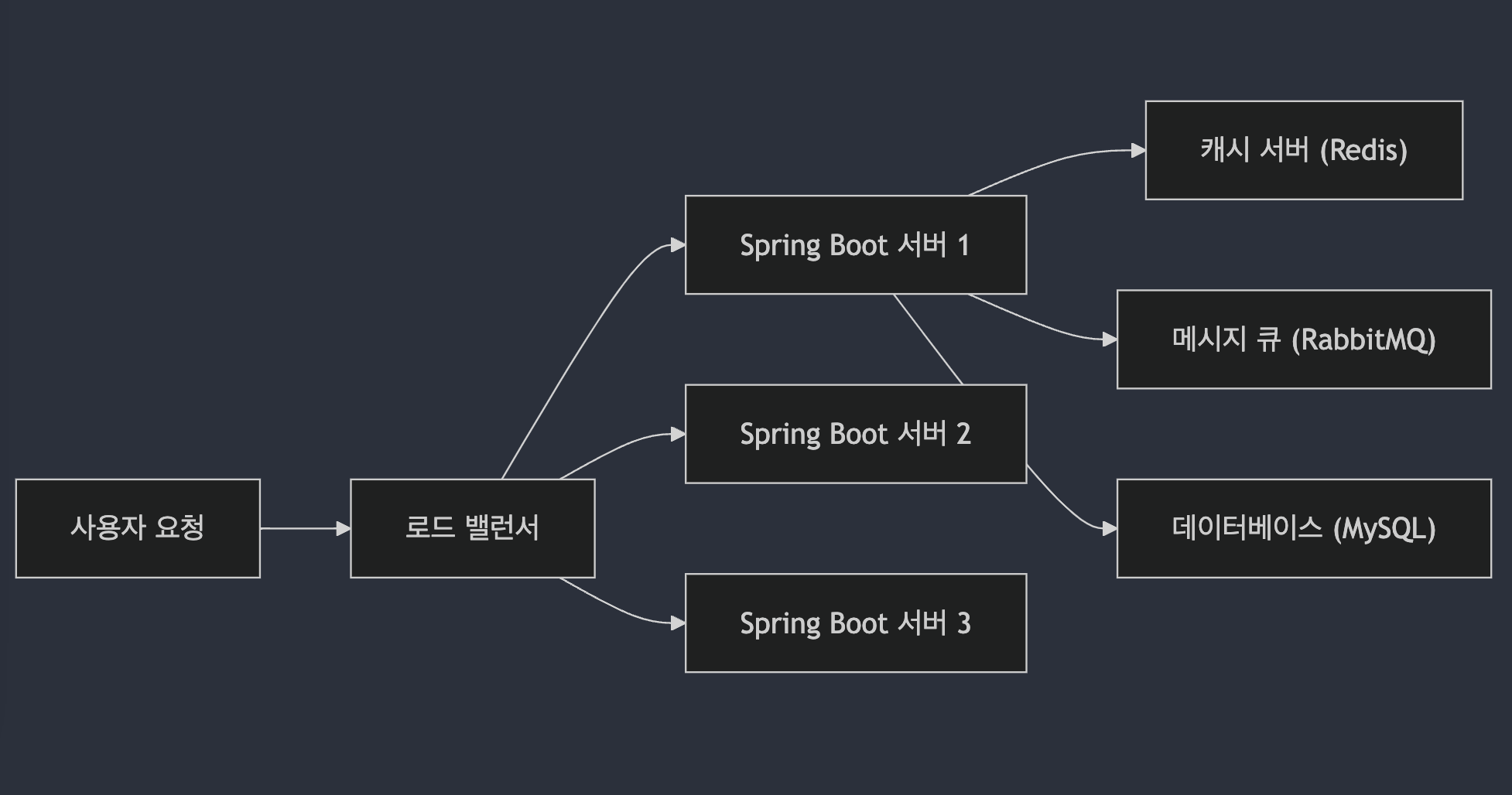
전체 아키텍쳐 다이어그램을 살펴보면
이런 식으로 표현할 수 있다. 사용자의 요청이 로드 밸런서를 통해 여러 서버에 분산되고, 각 서버는 캐싱, 비동기 처리. 메시지 큐, 데이터베이스를 활용해 안정적으로 응답을 제공하는 구조를 보여준다.