SQL 파싱, 최적화, 로우 소스 생성 과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해 두는 메모리 공간을 '라이브러리 캐시(Libray Cache)'라고 한다. 라이브러리 캐시는 SGA 구성요소다. SGA(System Global Area)는 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간이다.
SGA
사용자가 SQL문을 전달하면 DBMS는 SQL을 파싱한 후 해당 SQL이 라이브러리 캐시에 존재하는지부터 확인한다. 캐시에서 찾으면 곧바로 실행 단계로 넘어가지만, 찾지 못하면 최적화 단계를 거친다. SQL을 캐시에서 찾아 곧바로 실행단계로 넘어가는 것을 '소프트 파싱(Soft Parsing)'이라 하고, 찾는 데 실패해 최적화 및 로우 소스 생성 단계까지 모두 거치는 것을 '하드 파싱(Hard Parsing)'이라고 한다.
SQL 최적화 과정을 왜 하드(Hard)할까?
옵티마이저가 SQL을 최적화할 때 데이터베이스 사용자들이 보통 생각하는 것보다 훨씬 많은 일을 수행한다. 다섯 개 테이블을 조인하는 쿼리문 하나를 최적화하는 데도 무수히 많은 경우의 수가 존대한다. 조인 순서만 고려해도 120가지다. 여기서 NL 조인, 소트 머지 조인, 해시 조인 등 다양한 조인 방식이 있다. 테이블 전체를 스캔할지, 인데스를 이용할지 결정해야 하고, 인덱스 스캔에도 Index Range Scan, Index Unique Scan, Index Full Scan 등 다양한 방식이 제공된다. 이렇게 SQL 옵티마이저는 순식간에 엄청나게 많은 연산을 한다. 그 과정에서 옵티마이저가 사용하는 정보는 다음과 같다.
테이블, 컬럼, 인덱스 구조에 관한 기본 정보
오브젝트 통계 : 테이블 통계, 인덱스 통계. (히스토그램을 포함한) 컬럼 통계
시스템 통계 : CPU 속도, Single Block I/O 속도, Multiblock I/O 속도 등
옵티마이저 관련 파라미터
이렇게 어려운 작업을 거쳐 생성한 내부 프로시저를 한 번만 사용하고 버린다면 엄청난 비효율일 것이다. 라이브러리 캐시가 필요한 이유가 바로 여기에 있다.
사용자로부터 SQL을 전달받으면 가장 먼저 SQL 파서(Parser)가 파싱을 진행한다. SQL 파싱을 요약하면 다음과 같다.
파싱 트리 생성 : SQL문을 이루는 개별 구성요소를 분석해서 파싱 트리 생성
Syntax 체크 : 문법적 오류가 없는지 확인. 예를 들어, 사용할 수 없는 키워드를 사용했거나 순서가 바르지 않거나 누락된 키워드가 있는지 확인한다.
Semantic 체크 : 의미상 오류가 없는지 확인. 예를 들어, 존재하지 않는 테이블 또는 컬럼을 사용했는지, 사용한 오브젝트에 대한 권한이 있는지 확인한다.
2. SQL 최적화
그다음 단계가 SQL 최적화이고, 옵티마이저(Optimizer)가 그 역할을 맡는다. SQL 옵티마이저는 미리 수집한 시스템 및 오브젝트 통계정보를 바탕으로 다양한 실행경로를 생성해서 비교한 후 가장 효율적인 하나를 선택한다. 데이터베이스 성능을 결정하는 가장 핵심적인 엔진이다.
3. 로우 소스 생성
SQL 옵티마이저가 선택한 실행경로를 실제 실행 가능한 코드 또는 프로시저 형태로 포맷팅 하는 단계다. 로우 소스 생성시(Row-Source Generator)가 그 역할을 맡는다.
SQL 옵티마이저
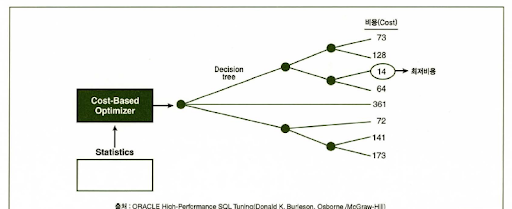
SQL 옵티마이저는 사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해 주는 DBMS의 핵심 엔진이다. 옵티마이저의 최적화 단계를 요약하면 다음과 같다.
사용자로부터 전달받은 쿼리를 수행하는 데 후보군이 될만한 실행계획들을 찾아낸다.
데이터 딕셔너리(Data Dictionary)에 미리 수집해 둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
최저 비용을 나타내는 실행계획을 선택한다.
실행계획과 비용
SQL 옵티마이저는 자동차 네비게이션과 여러모로 흡사하다. 경로 요약이나 모의 주행 같은 기능이 그렇다.
DBMS에도 SQL 실행경로 미리보기 기능이 있다. 실행계획(Execution Plan)이 바로 그것이다. SQL 옵티마이저가 생성한 처리절차를 사용자가 확인할 수 있게 아래와 같이 트리 구조로 표현한 것이 실행계획이다.
실행계획
미리보기 기능을 통해 자신이 작성한 SQL이 테이블을 스캔하는지 인덱스를 스캔하는지, 인덱스를 스캔한다면 어떤 인덱스인지를 확인할 수 있고, 예상과 다른 방식으로 처리된다면 실행경로를 변경할 수 있다.
옵티마이저가 특정 실행계획을 선택하는 근거는 무엇일까?
비용을 통해 선택을 하게 된다. 비용(Cost)은 쿼리를 수행하는 동안 발생할 것으로 예상하는 I/O 횟수 또는 예상 소요시간을 표현한 값이다.
하지만 SQL 실행계획에 표시되는 Cost는 어디까지나 예상치다. 실행경로를 선택하기 위해 옵티마이저가 여러 통계정보를 활용해서 계산해 낸 값이다. 실측치가 아니므로 실제 수행할 때 발생하는 I/O 또는 시간과 많은 차이가 난다.
옵티마이저 힌트
힌트 사용법은 아래와 같다. 주석 기호에 '+'를 붙이면 된다.
SELECT /*+ INDEX(A 고객_PK) */
고객명, 연락처, 주소, 가입일시
FROM 고객 A
WHERE 고객ID = :cust_id;
주의사항
/*+ INDEX(A A_X01) INDEX(B, B_X03) */ -> 모두 유효
/*+ INDEX(C), FULL(D) */ -> 첫 번째 힌트만 유효
SELECT /*+ FULL(SCOTT.EMP) */ -> 스키마명까지 명시하면 무효가 된다.
FROM EMP;
SELECT /*+ FULL(EMP) */ -> FROM 절 테이블명 옆에 ALIAS를 지정했다면, 힌트에도 반드시 ALIAS를 사용해야 한다.
FROM EMP E
Lock은 데이터베이스의 특징을 결정짓는 가장 핵심적인 메커니즘이다. 자신이 사용하는 데이터베이스의 고유한 Lock 메커니즘을 이해하지 못한다면, 고품질, 고성능 애플리케이션을 구축하기 어렵다.
오라클 Lock
오라클은 공유 리소스와 사용자 데이터를 보호할 목적으로 DML Lock, DDL Lock, 래치, 버퍼 Lock, 라이브러리 캐시 Lock/pin 등 다양한 종류의 Lock을 사용한다. 이 외에도 내부에 더 많은 종류의 Lock 이 존재한다.
애플링케이션 개발 측면에서 가장 중요하게 다루어야 할 Lock은 무엇보다 DML Lock 이다. DML Lock은 다중 트랜잭션이 동시에 액세스하는 사용자 데이터의 무결성을 보호해 준다.
테이블 Lock
로우 Lock
DML 로우 Lock
DML 로우 Lock은, 두 개의 동시 트랜잭션이 같은 로우를 변경하는 것을 방지한다. 하나의 로우를 변경하려면 로우 Lock을 먼저 설정해야 한다. 어떤 DBMS이든지 DML 로우 Lock에는 배타적 모드를 사용하므로 UPDATE 또는 DELETE를 진행 중인(아직 커밋하지 않은) 로우를 다른 트랜잭션이 UPDATE 하거나 DELETE 할 수 없다.
INSERT에 대한 로우 Lock 경합은 Unique 인덱스가 있을 때만 발생한다. 즉, Unique 인덱스가 있는 상황에서 두 트랜잭션이 같은 값을 입력하라고 할 때, 블로킹이 발생한다. 블로킹이 발생하면, 후행 트랜잭션이 기다렸다가 선행 트랜잭션이 커밋하면 INSERT에 실패하고, 롤백하면 성공한다. 두 트랜잭션이 서로 다른 값을 입력하거나 Unique 인덱스가 아예 없으면, INSERT에 대한 로우 Lock 경합은 발생하지 않는다.
MVCC 모델을 사용하는 오라클은(for update절이 없는) SELECT 문에 로우 Lock을 사용하지 않는다. 오라클은 다른 트랜잭션이 변경한 로우를 읽을 때 복사본 블록을 만들어서 쿼리가 '시작된 지점'으로 되돌려서 읽는다. 변경이 진행 중인(아직 커밋하지 않은) 로우를 읽을 때도 Lock이 풀릴 때까지 기다리지 않고 복사본을 만들어서 읽는다. 따라서 SELECT 문에 Lock을 사용할 필요가 없다.
결국, 오라클에서는 DML과 SELECT는 서로 진행을 방해하지 않는다. 물론 SELECTㄲ리도 서로 방해하지 않는다. DML끼리는 서로 방해할 수 있는데, 이는 어떤 DBMS를 사용하더라도 마찬가지다.
참고로, MVCC 모델을 사용하지 않는 DBMS는 SELECT 문에 공유 Lock을 사용한다. 공유 Lock끼리는 호환된다. 두 트랜잭션이 같이 Lock을 설정할 수 있다는 뜻이다. 반면, 공유 Lock과 배타적 Lock은 호환되지 않기 때문에 DML과 SELECT가 서로 진행을 방해할 수 있다.
즉, 다른 트랜잭션이 읽고 있는 로우를 변경하려면 다음 레코드로 이동할 때까지 기다려야 하고, 다른 트랜잭션이 변경 중인 로우를 읽으려면 커밋할 때까지 기다려야 한다.
DML 테이블 Lock
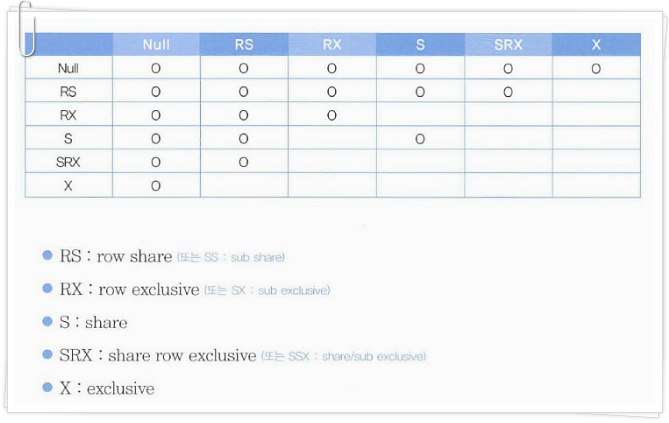
오라클은 DML 로우 Lock을 설정하기에 앞서 테이블 Lock을 먼저 설정한다. 현재 트랜잭션이 갱신 중인 테이블 구조를 다른 트랜잭션이 변경하지 못하게 막기 위해서다. 테이블 Lock을 "TM Lock"이라고 부르기도 한다.
테이블 Lock (O 표시는 두 모드 간에 호환성이 있음을 의미한다.)
선행 트랜잭션과 호환되지 않는 모드로 테이블 Lock을 설정하려는 후행 트랜잭션은 대기하거나 작업을 포기해야 한다.
테이블 Lock이라고 하면, 테이블 전체에 Lock이 걸린다고 생각하기 쉽다. 그래서 다른 트랜잭션이 더는 레코드를 추가하거나 갱신하지 못한다고 생각하는 사람이 많다. 하지만 DML을 수행하기 전에 항상 테이블 Lock을 먼저 설정하므로 그렇게 이해하는 것은 맞지 않다. 하나의 로우를 변경하기 위해 테이블 전체에 Lock을 건다면 동시성이 좋은 어플리케이션을 구현하기 어렵다.
오라클에서 말하는 테이블 Lock은, 자신(테이블 Lock을 설정한 트랜잭션)이 해당 테이블에서 현재 어떤 작업이 수행 중인지를 알리는 일종의 푯말이다. 위의 표처럼 테이블 Lock에는 여러 가지 모드가 있고, 어떤 모드를 사용하는지에 따라 후행 트랜잭션이 수행할 수 있는 작업의 범위가 결정된다.
예를 들어, DDL을 이용해 테이블 구조를 변경하려는 트랜잭션은 해당 테이블에 TM Lock이 설정돼 있는지를 먼저 확인한다. TM Lock을 RX(=SX) 모드로 설정한 트랜잭션이 하나라도 있으면, 현재 테이블을 갱신 중인 트랜잭션이 있다는 신호다. 따라서 ORA-00054 메시지를 남기고 작업을 멈춘다.
Lock을 푸는 열쇠, 커밋
블로킹(Blocking)은 선행 트랜잭션이 설정한 Lock 때문에 후행 트랜잭션이 작업을 진행하지 못하고 멈춰 있는 상태를 말한다. 이것을 해소하는 방법은 커밋(또는 롤백)뿐이다.
교착상태(DeadLock)는 두 트랜잭션이 각각 특정 리소스에 Lock을 설정한 상태에서 맞은편 트랜잭션이 Lock을 설정한 리소스에 또 Lock을 설정하려고 진행하는 상황을 말한다. 교착상태가 발생하면 둘 중 하나가 뒤로 물러나지 않으면 영영 풀릴 수 없다.
오라클에서 교착상태가 발생하면, 이를 먼저 인지한 트랜잭션이 문장 수준 롤백을 진행한 후에 아래 에러 메시지를 던진다. 교착상태를 발생시킨 문장 하나만 롤백하는 것이다.
ORA-00060 : deadlock detected while waiting for resource
이제 교착상태는 해소됐지만 블로킹 상태에 놓이게 된다. 따라서 이 메시지를 받은 트랜잭션은 커밋 또는 롤백을 결정해야 한다. 만약 프로그램 내에서 이 에러에 대한 예외처리를 하지 않는다면 대기 상태를 지속하게 되므로 주의가 필요하다.
트랜잭션이 너무 길면, 트랜잭션을 롤백해야 할 때 너무 많은 시간이 걸려 고생할 수 있다. 따라서 같은 데이터를 갱신하는 트랜잭션이 동시에 실행되지 않도록 애플리케이션을 설계해야 하고, DML Lock 때문에 동시성이 저하되지 않도록 적절한 시점에 커밋해야 한다.
배치 커밋 명령어
WAIT(Default) : LGWR가 로그버퍼를 파일에 기록했다는 완료 메시지를 받을 때까지 기다린다(동기식 커밋)
NOWWAIT : LGWR의 완료 메시지를 기다리지 않고 바로 다음 트랜잭션을 진행한다(비동기식 커밋)
IMMEDIATE(Default) : 커밋 명령을 받을 때마다 LGWR가 로그 버퍼를 파일에 기록한다.
동시성 제어는 비관적 동시성 제어와 낙관적 동시성 제어로 나뉜다. 비관적 동시성 제어(Pessimistic Concurrency Control)는 사용자들이 같은 데이터를 동시에 수정할 것으로 가정한다. 따라서 한 사용자가 데이터를 읽는 시점에 Lock을 걸고 조회 또는 갱신처리가 완료될 때까지 이를 유지한다. Lock은 첫 번째 사용자가 트랜잭션을 완료하기 전까지 다른 사용자들이 같은 데이터를 수정할 수 없게 만들기 때문에 비관적 동시성 제어를 잘못 사용하면 동시성이 나빠진다.
반면, 낙관적 동시성 제어(Optimistic Concurrency Control)는 사용자들이 같은 데이터를 동시에 수정하지 않을 것으로 가정한다. 따라서 데이터를 읽을 때 Lock을 설정하지 않는다. 그런데 낙관적 입장에서 섰다고 해서 동시 트랜잭션에 의한 잘못된 데이터 갱신을 신경 쓰지 않아도 된다는 것은 아니다. 읽는 시점에 Lock을 사용하지 않았지만, 데이터를 수정하고자 하는 시점에 앞서 읽은 데이터가 다른 사용자에 의해 변경되었는지 반드시 검사해야 한다.
비관적 동시성 제어
우수 고객을 대상으로 적립포인트를 제공하는 이벤트를 제공한다고 가정해보자 이때 밑에 예시처럼 고객의 다양한 실적정보를 읽고 복잡한 산출공식을 이용해 적립포인트를 계산하는 동안(SELECT 문 이후, UPDATE 문 이전) 다른 트랜잭션이 같은 고객의 실적정보를 변경하다면 문제가 생길 수 있다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적 from 고객
where 고객포인트 = :cust_num;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트 where 고객번호 = :cust_num
하지만, 아래와 같이 SELECT 문에 FOR UPDATE를 사용하면 고객 레코드에 Lock을 설정하므로 데이터가 잘못 갱신되는 문제를 방지할 수 있다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적 from 고객
where 고객포인트 = :cust_num for update;
비관적 동시성 제어는 자칫 시스템 동시성을 심각하게 떨어뜨릴 우려가 있지만, FOR UPDATE에 WAIT 또는 NOWAIT 옵션을 함께 사용하면 Lock을 얻기 위해 무한정 기다리지 않아도 된다.
for update nowait -- 대기없이 Exception(ORA-00054)을 던짐
for update wait 3 -- 3초 대기 후 Exception(ORA-30006)을 던짐
WAIT 또는 NOWAIT 옵션을 사용하면, 다른 트랜잭션에 의해 Lock이 걸렸을 때, Exception을 만나게 되므로 "다른 사용자에 의해 변경 중이므로 다시 시도하십시오" 라는 메시지를 출력하면서 트랜잭션을 종료할 수 있다. 따라서 오히려 동시성을 증가시키게 된다.
큐 테이블에 쌓인 고객 입금 정보를 일정한 시간 간격으로 읽어서 입금 테이블에 반영하는 데몬 프로그램이 있다고 가정하다.
데몬이 여러 개이므로 Lock이 걸릴 수 있는 상황이다. Lock이 걸리면 3초간 대기했다가 다음에 다시 시도하게 하려고 아래와 같이 for update wait 3 옵션을 지정했다. 큐에 쌓인 데이터를 한 번에 다 읽어서 처리하면 Lock이 풀릴 때까지 다른 데몬이 오래 걸릴 수 있으므로 고객 정보를 100개씩만 읽도록 했다.
select cust_id, rcpt_amt from cust_rcpt_Q
where yn_upd = 'Y' and rownum <= 100 FOR UPDATE WAIT 3;
이럴 때 아래와 같이 skip locked 옵션을 사용하면, Lock이 걸린 레코드는 생략하고 다음 레코드를 계속 읽도록 구현할 수 있다.
select cust_id, rcpt_nm from cust_rcpt_Q
where yn_upd = 'Y' FOR UPDATE SKIP LOCKED;
낙관적 동시성 제어
낙관적 동시성 제어 예시를 보자.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적 into :a, :b, :c, :d
from 고객
where 고객번호 = :cust_num;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트
where 고객번호 = :cust_num
and 적립포인트 = :a
and 방문횟수 = :b
and 최근방문일시 = :c
and 구매실적 = :d;
if sql%rowcount = 0 than
alert("다른 사용자에 의해 변경되었습니다.");
end if;
SELECT 문에서 읽은 컬럼이 매우 많다면 UPDATE 문에 조건절을 일일이 기술하는 것이 귀찮을 것이다. 만약 UPDATE 대상 테이블에 최종변경일시를 관리하는 컬럼이 있다면, 이를 조건절에 넣어 간단하게 해당 레코드의 갱신여부를 판단할 수 있다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적, 변경일시
into :a, :b, :c, :d, :mod_dt
from 고객
where 고객번호 = :cust_num;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트, 변경일시 = SYSDATE
where 고객번호 = :cust_num
and 변경일시 = :mod_dt; -> 최종 변경일시가 앞서 읽은 값과 같은지 비교
if sql%rowcount = 0 than
alert("다른 사용자에 의해 변경되었습니다.");
end if;
낙관적 동시성 제어에서도 UPDATE 전에 아래 SELECT 문을 한 번 더 수행함으로써 Lock에 대한 예외처리를 한다면, 다른 트랜잭션이 설정한 Lock을 기다리지 않게 구현할 수 있다.
select 고객번호
from 고객
where 고객번호 = :cust_num
and 변경일시 = :mod_dt
for update nowait;
동시성 제어 없는 낙관적 프로그래밍
낙관적 동시성 제어를 사용하면 Lock이 유지되는 시간이 매우 짧아져 동시성을 높이는 데 매우 유리하다. 하지만 다른 사용자가 같은 데이터를 변경했는지 검사하고 그에 따라 처리 방향성을 결정하는 귀찮은 절차가 뒤따른다.
예를 들어, 온라인 쇼핑몰에서 특정 상품을 조회해서 결제를 완료하는 순간까지를 하나의 트랜잭션으로 정의했다고 가정해보자.
위의 그림에서 보듯, TX1이 t1 시점에 상품을 조회할 때는 가격기 1,000원이었다. 주문을 진행하는 동안 TX2에 의해 가격이 1,200원으로 수정되었다면, TX1이 최종 결제 버튼을 클릭하는 순간 어떻게 처리해야 할까? 상품 가격의 변경 여부를 체크함으로써 해당 주문을 취소시키거나 사용자에게 변경사실을 알리고 처리방향을 확인받는 프로레스를 거쳐야 한다.
insert into 주문
select :상품코드, :고객ID, :주문일시, :상점번호, ....
from 상품
where 상품코드 = :상품코드
and 가격 = :가격; -- 주문을 시작한 시점 가격
if sql%rowcount = 0 than
alert("상품 가격이 변경되었습니다.");
end if;
하지만 이런 로직은 찾기 힘들다. 주문을 진행하는 동안 상품 공급업체가 가격을 변경하지 않을 것이라고 낙관적으로 생각하기 때문이다.
정렬된 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾는 과정이다. 즉, 인덱스 스캔 시작점을 찾는 과정이다.
인덱스 수직적 탐색은 루트(Root) 블록에서부터 시작한다. 루트를 포함해 브랜치(Branch) 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖는다. 루트에서 시작하여 리프(Leaf) 블록까지 수직적 탐색이 가능한 이유다.
수직적 탐색 과정에 찾고자 하는 값보다 크거나 같은 값을 만나면, 바로 직전 레코드가 가리키는 하위 블록으로 이동한다.
여기서 중요한 것은 수직적 탐색은 조건을 만족하는 레코드를 찾는 과정이 아니라 조건을 만족하는 첫 번째 레코드를 찾는 과정임을 반드시 기억해야 한다.
인덱스 수평적 탐색
수직적 탐색을 통해 스캔 시작점을 찾았다면, 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔한다. 인덱스에서 본격적으로 데이터를 찾는 과정이다. 인덱스 리프 블록끼리는 서로 앞뒤 블록에 대한 주소값을 갖는다. 즉, 양방향 연결 리스트(double linked list) 구조다. 좌에서 우로, 또는 우에서 좌로 수평적 탐색이 가능한 이유다.
인덱스를 수평적으로 탐색하는 이유는 첫째, 조건절을 만족하는 데이터를 모두 찾기 위해서고 둘째, ROWID를 얻기 위해서다. 필요한 컬럼을 인덱스가 모두 갖고 있어 인덱스만 스캔하고 끝나는 경우도 있지만, 일반적으로 인덱스를 스캔하고서 테이블도 액세스 한다. 이때 ROWID가 필요하다.
인덱스는 WHERE 절에 자주 등장하는 컬럼에 지정하거나, ORDER BY에 자주 사용되는 컬럼에 사용해주면 좋다.
선택도가 낮은 컬럼을 앞쪽에 두고 결합인덱스를 생성해야 검사 횟수를 줄일 수 있어 성능에 유리하다.