데이터를 찾는 두 가지 방법
어떤 초등학교를 방문해 '홍길동' 학생을 찾는 방법은 두 가지다. 첫째는, 1학년 1반부터 6학년 맨 마지막 반까지 모든 교실을 돌며 홍길동 학생을 찾는 것이다. 둘째는, 교무실에서 학생 명부를 조회해 홍길동 학생이 있는 교실만 찾아가는 것이다. 둘 중 어느 쪽이 빠를까? 홍길동 학생이 많다면 전자가 빠르고, 몇 안되면 후자가 빠르다.
데이터베이스 테이블에서 데이터를 찾는 방법도 아래 두 가지다. 수십 년에 걸쳐 DBMS가 발전해 왔는데도 이 두 방법에서 크게 벗어나지 못하고 있다.
- 테이블 전체를 스캔한다.
- 인덱스를 이용한다.
인덱스 튜닝의 두 가지 핵심요소
인덱스는 큰 테이블에서 소량 데이터를 검색할 때 사용한다. 온라인 트랜잭션 처리 시스템에서는 소량 데이터를 주로 검색하므로 인덱스 튜닝이 무엇보다 중요하다.
세부적인 인덱스 튜닝 방법으로 여러 가지가 있지만, 핵심요소는 크게 두 가지로 나뉜다. 첫번째는 인덱스 스캔 과정에서 발생하는 비효율을 줄이는 것이다. 즉 '인덱스 스캔 효율화 튜닝'이다.
예를 들어, 학생명부에서 키가 170cm ~ 173cm인 홍길동 학생을 찾는 경우로 예를 들어보자. 학생명부를 이름과 키순으로 정렬해 두었다면, 소량만 스캔하면 된다.
| 이름 | 키 | 학년-반-번호 |
| 강수지 | 171 | 4학년 3반 37번 |
| 김철수 | 180 | 3학년 2반 13번 |
| ... | ||
| 이영희 | 172 | 6학년 4반 19번 |
| ... | ||
| 홍길동 | 168 | 2학년 6반 24번 |
| 홍길동 | 170 | 5학년 1반 16번 |
| 홍길동 | 173 | 1학년 5반 15번 |
| .... |
반면, 학생명부를 시력과 이름순으로 정렬해 두었다면, 똑같이 두 명을 찾는데도 많은 양을 스캔해야 한다.
| 시력 | 이름 | 학년-반-번호 |
| 168 | 홍길동 | |
| .... | ||
| 170 | 홍길동 | |
| 171 | 강수지 | |
| 172 | 이영희 | |
| 173 | 홍길동 | |
| ... | ||
| 180 | 김철수 |
인덱스 튜닝의 두 번째 핵심요소는 테이블 액세스 횟수를 줄이는 것이다. 인덱스 스캔 후 테이블 레코드를 액세스할 때 랜덤 I/O 방식을 사용하므로 이를 '랜덤 액세스 최소화 튜닝'이라고 한다.
인덱스 스캔 효율화 튜닝과 랜덤 액세스 최소화 튜닝 둘 다 중요하지만, 더 중요한 하나를 고른다면 랜덤 액세스 최소화 튜닝이다. 성능에 미치는 영향이 크기 때문이다. SQL 튜닝은 랜덤 I/O와의 전쟁이다.
인덱스 구조
인덱스는 대용량 테이블에서 필요한 데이터만 빠르게 효율적으로 액세스하기 위해 사용하는 오브젝트다. 모든 책 뒤쪽에 있는 색인과 같은 역할을 한다. 데이터베스에서 인덱스 없이 데이터를 검색하려면, 테이블을 처음부터 끝까지 모두 읽어야 한다. 반면, 인덱스를 이용하면 일부만 읽고 멈출 수 있다. 즉, 범위 스캔(Range Scan)이 가능하다. 범위 스캔이 가능한 이유는 인덱스가 정렬돼 있기 때문이다.
DBMS는 일반적으로 B*Tree 인덱스를 사용한다. 나무(Tree)를 거꾸로 뒤집은 모양이여서 뿌리(Root)가 위쪽에 있고, 가지(Branch)를 거쳐 맨 아래에 잎사귀(Leaf)가 있다.
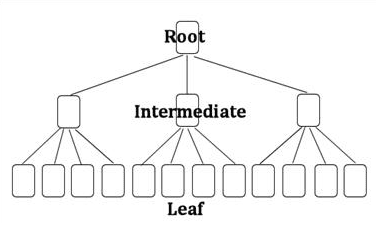
루트와 브랜치 블록에 있는 각 레코드는 하위 블록에 대한 주소값을 갖는다. 키값은 하위 블록에 저장된 키값의 범위를 나타낸다.
- ROWID = 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소 = 데이터 파일 번호 + 블록 번호
- 블록 번호 : 데이터파일 내에서 부여한 상대적 순번
- 로우 번호 : 블록 내 순번
인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 나눌 수 있다.
- 수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
인덱스 수직적 탐색
정렬된 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾는 과정이다. 즉, 인덱스 스캔 시작지점을 찾는 과정이다.
인덱스 수직적 탐색은 루트(Root) 블록에서부터 시작한다. 루트를 포함해 브랜치(Branch) 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖는다. 루트에서 시작해 리프(Leaf) 블록까지 수직적 탐색이 가능한 이유다.
수직적 탐색 과정에 찾고자 하는 값보다 크거나 같은 값을 만나면, 바로 직전 레코드가 가리키는 하위 블록으로 이동한다.
수직적 탐색은 '조건을 만족하는 레코드'를 찾는 과정이 아니라 '조건을 만족하는 첫 번째 레코드'를 찾는 과정임을 반드시 기억해야 한다.
인덱스 수평적 탐색
수직적 탐색을 통해 스캔 시작점을 찾았으면, 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔한다. 인덱스에서 본격적으로 데이터를 찾는 과정이다.
인덱스 리프 블록끼리는 서로 앞뒤 블록에 대한 주소값을 갖는다. 즉, 양방향 연결 리스트(double linked list) 구조다. 좌에서 우로, 또는 우에서 좌로 수평적 탐색이 가능한 이유다.
인덱스를 수평적으로 탐색하는 이유는 첫째, 조건절을 만족하는 데이터를 모두 찾기 위해서고 둘째, ROWID를 얻기 위해서다.
'Back-End > DB' 카테고리의 다른 글
| 오라클 MERGE INTO 구문과 INACTIVE (1) | 2024.10.18 |
|---|---|
| DB Connection is not associated (1) | 2024.09.10 |
| 캐시 탐색 메커니즘 (2) | 2024.07.30 |
| 데이터 저장 구조 및 I/O 메커니즘 (2) | 2024.07.29 |
| SQL 공유 및 재사용 (0) | 2024.07.26 |